I'm Anti-LLM.
Everything on this website was created by me, by my own mind and my own hands on a keyboard, etc., or from tools I reasonably believe to have been so by someone else. It's probably impossible to completely avoid AI, and I don't sweat the small stuff, but it is never deliberate, and I actively go out of my way to avoid it wherever possible.
I am Anti-LLM.
I wish this didn't need an explanation, but invariably the question is asked by colleagues and friends who say things like "AI is here to stay, get with the times", or "It's just like any other new technology that was initially rejected." And I understand both of these impulses: LLMs, though profoundly functionally flawed, appear like magic to a technophillic eye, and look like free candy to CEOs, and appear ubiquitous and inevitable to everyone on the ground stuck with the consequences of the technocrats forcing it down our throats.
LLMs, what are now in common parlance simply called "AI" -- although I dislike this name[1] -- are basically what happens when you take a neural network and feed it the entire Internet. OpenAI originally proposed this as a research project, and that research was fascinating because it stood on the shoulders of giants to predict what might happen when you expand an observation about the behavior of neural networks as their size increases. I'm hand-waving here, but the point is, the research was interesting, and the result was almost spooky. Neural networks are inherently pattern-matching machines, and LLMs had ripe fruit to pick from the linguistics tree. Humans, it turns out (unsurprisingly to many), are predictable. And thus was born GPT.
I reject what happened after that: The rapid commercialization of LLMs, the implementation of chatbots and other LLM functionality into every nook and cranny of daily life, the barrage of technophiles claiming they're the future and dismissing the difference between a human artist and a machine spitting out pixels, the biggest economic bet of our lifetimes on a technology that we can't even get reliable results from.
And I reject what happened before that: The effectively slave labor that trained ImageNet, the reckless disregard for consent or intellectual property laws in pursuit of data to feed LLMs[2][3], the transformation of OpenAI from research to for-profit.
LLMs are an inherently unethical use of computer technology because they rely on unethical gathering and consumption of data. No ethical data-gathering practice is capable of providing them with even the minimum data they require to exist, let alone doing so affordably, and so the huge coprorations that created them -- inevitably, since the cost of electricity and computing resources to do so is actually that huge -- simply went ahead anyway, knowing full well they probably could not be held accountable.
Worse than that, LLMs as they are deployed in real life are devaluing people. Software engineers are now, at most companies, effectively required to use LLM-based code assistants as a productivity boost, after many of their colleagues were laid off to cut costs and push that burden onto the remaining staff. The arts are in shambles, with AI "art" polluting every corner of the Internet and every space where creative people meet: writing books and stories, making music, painting, sculpture, every aspect of human creativity that has ever been demonstrated online has been consumed for the benefit of LLM training, without having either paid those creators, gathered their consent, or made any plans to ensure artists can continue making a living. (And what happens when artists can no longer make a living? We just get more AI art, rehashing the same ideas on an endless loop, because an LLM is only capable of recombining training data, it is not capable of novel thought.)
As if to throw icing on the cake, in my line of work the bare minimum acceptable uptime for any service is "three nines" -- 99.9% -- and none of OpenAI, Claude (Anthropic), or Gemini (Google) can meet that bar. Claude was even having an outage while I took these screenshots!
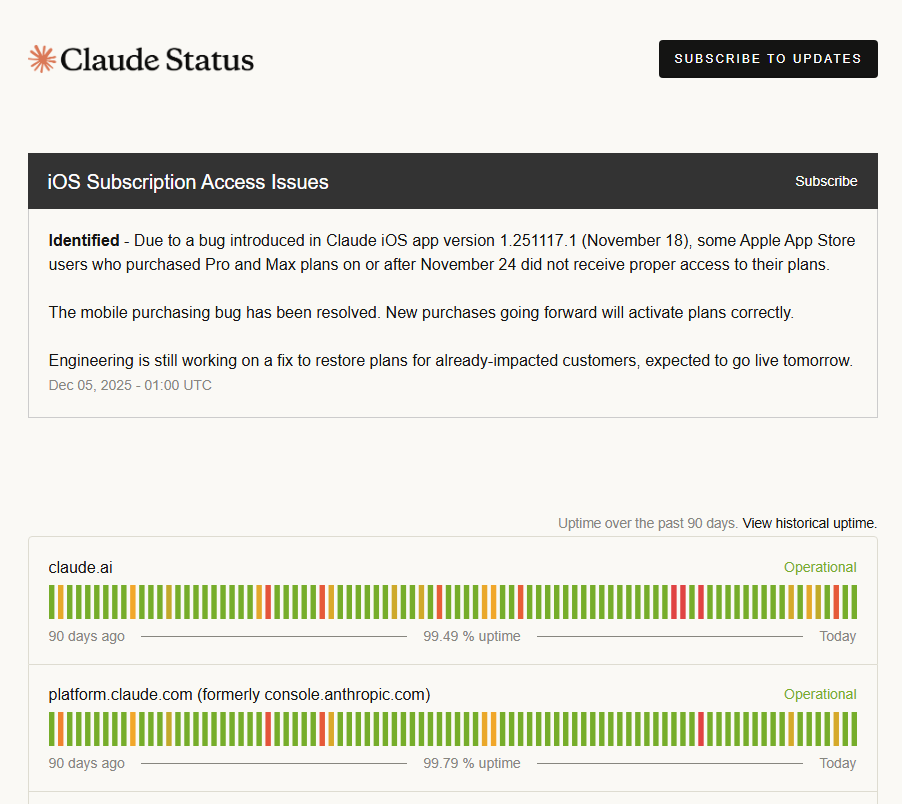
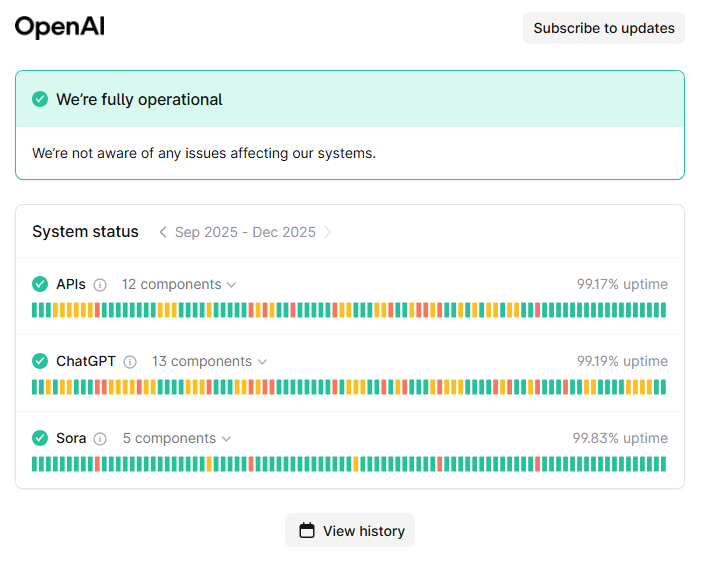
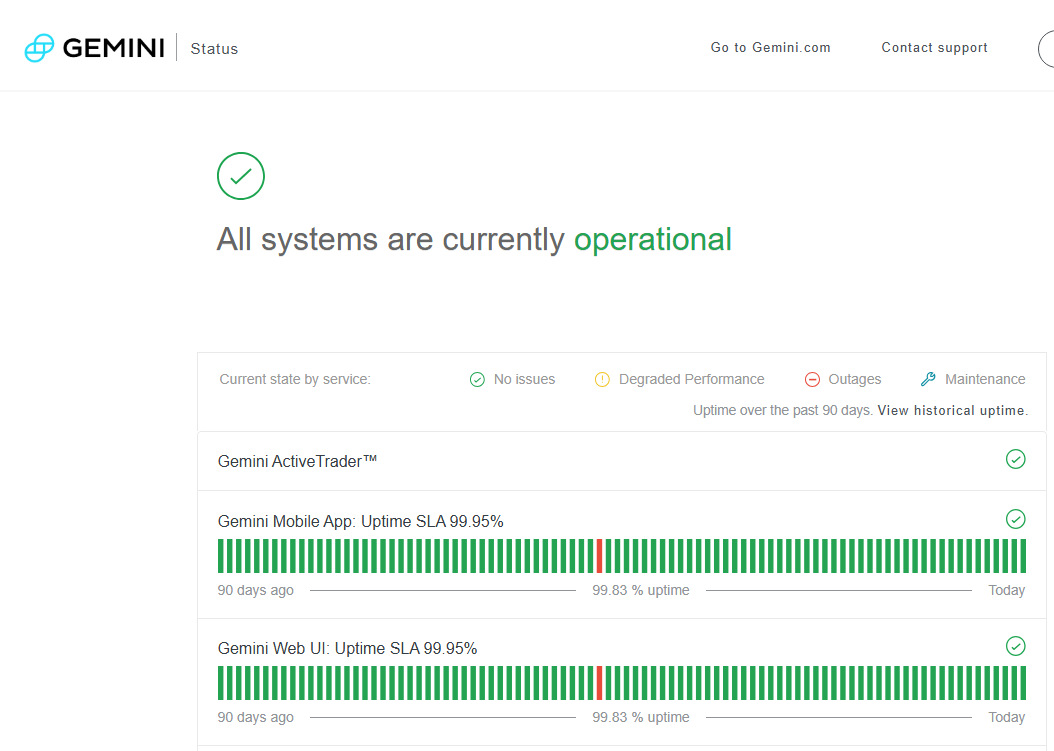
I am not alone.
While my stance is my own, it's worth pointing out that I'm not alone -- other people hold similar opinions on the creative side, on the utility side, on the ethics side. Here I will highlight a few resources to peruse at your leisure:
Where I stand
I believe humans should be the only creative agents. Machines that facilitate human creativity are welcome to me. Machines that replace - even partially - that same creativity are not. LLMs don't just partially replace humans, they're wiping out entire creative demographics.
I believe that ethical collection and use of data matters, including intellectual property law that (for its many flaws) is the backbone of shared creativity.
To that end, I make a clear, firm, and unequivocal statement that I oppose LLMs on ethical grounds, no argument about how useful or ubiquitous they are, or how I will be left behind, will ever sway me.
To my readers, I have only one request: Respect my wishes. Don't copy my text into a chatbot to summarize it. If you are in a position to do so, don't scan my website for LLM training data. I welcome human use of my creative output in your own, or if what I said is helpful, I'm glad to hear it, and I want to make sure it is helpful because someone read it.
I probably cannot do anything about it if you do, since a website is a fundamental unit of existence in a digital world, and I'm neither wealthy nor influential enough to fight back. But I can at least set a boundary and ask that it be respected. To those that don't, just know you have violated me.
Footnotes
[1] There are many ways to do AI that have been done for decades which I not only don't object to, but actively embrace. Neural networks are useful tools, as are markov chains, decision trees, evolutionary algorithms, and the myriad of other tools that predated LLMs.)
[2] Including things like ReCaptcha which had become ubiquitous to block access to non-humans on websites, but which was used to train Google's machine learning models. There is an argument that I've heard many times now that you can simply not consent to helping ReCaptcha by not solving Captchas. That's like saying you can object to climate change by not using electricity from coal. Depending on where you live, good luck with that. And that's the point.
[3] LLMs are so hungry for data that we've consumed not only the entire publicly accessible Internet for all intents and purposes, but also an immense amount of private information: copyrighted works like books, movies, and music; private or reasonably construed as private data like social media posts and e-mails; you name it, an LLM or five have probably eaten it, whether you consented or not, and you never even had the opportunity to opt out.